Alfred : dans les coulisses d'une plateforme de chatbot IA en Python

Alfred est une plateforme de chatbot IA multi-tenant que j’ai conçue et développée de bout en bout, en Python. Derrière une simple bulle de chat se cache une mécanique pensée pour un objectif précis : mettre l’IA au service du dialogue sans jamais lui confier les données sensibles de l’entreprise. Voici une visite guidée de ses fonctionnalités et de son architecture.
Le principe : le LLM orchestre, il ne détient pas
La plupart des chatbots envoient tout au modèle de langage : la question, les données métier, les résultats d’API. Alfred prend le parti inverse. Le LLM sert uniquement à comprendre l’intention et à router vers la bonne action ; il produit un JSON structuré {intent, action, parameters, response}. Le résultat de l’action, lui, est renvoyé directement à l’application, sans repasser par le modèle.
 Le flux d’une requête : les canaux passent par l’API FastAPI, qui route via le LLM puis exécute l’action, avec la donnée sensible qui reste hors du LLM.
Le flux d’une requête : les canaux passent par l’API FastAPI, qui route via le LLM puis exécute l’action, avec la donnée sensible qui reste hors du LLM.
Ce choix d’architecture (paramétrable action par action via process_hook_in_llm = false) est la garantie de confidentialité au cœur de la plateforme : une donnée technique ou personnelle peut alimenter la réponse affichée à l’utilisateur sans jamais être transmise à un fournisseur d’IA tiers.
LiteLLM : un modèle, tous les fournisseurs
Le branchement au LLM passe par LiteLLM, une couche d’abstraction qui expose une interface unifiée quel que soit le fournisseur derrière : OpenAI, Anthropic, Mistral, ou un modèle local via Ollama. On change de modèle depuis le back-office, sans toucher au code métier.
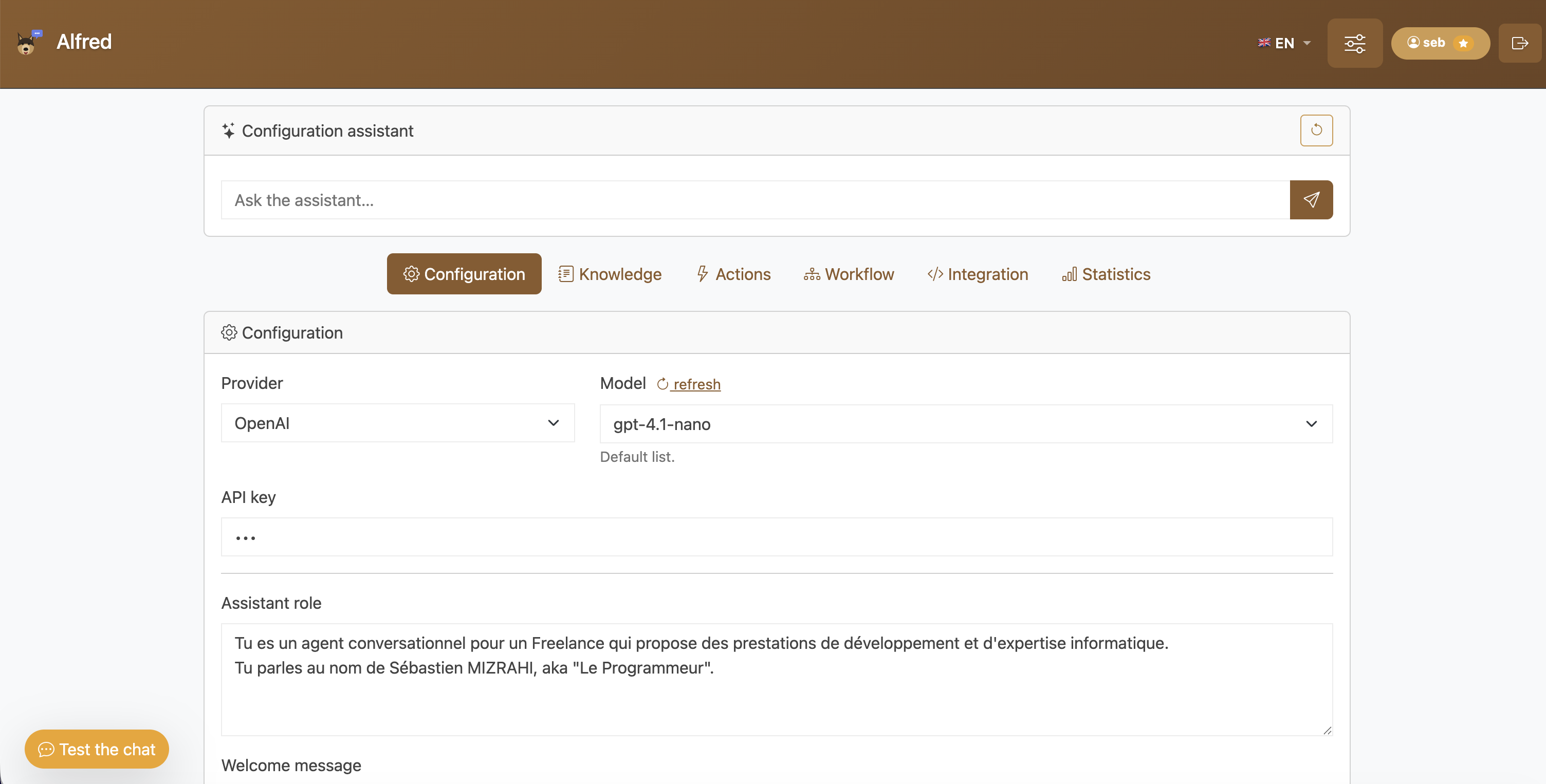 Le tableau de bord : choix du fournisseur et du modèle, clé API, rôle de l’assistant, ainsi qu’un assistant de configuration en langage naturel.
Le tableau de bord : choix du fournisseur et du modèle, clé API, rôle de l’assistant, ainsi qu’un assistant de configuration en langage naturel.
Le routage lui-même peut fonctionner de deux façons : le contrat JSON dans le prompt, ou le function-calling natif de LiteLLM (activable par client). Dans les deux cas, le LLM se contente de router. Il ne reçoit jamais les résultats des outils.
Actions & hooks : quatre façons d’agir
Quand une intention correspond à une action, Alfred l’exécute via l’un de quatre backends, tous traités de façon identique côté flux :
- Hook Python : un plugin auto-découvert, déclaré par un simple décorateur
@hook("action"). - Webhook HTTP : un appel à une URL externe quand l’action est déclenchée.
- Outil MCP : Alfred est client MCP (transports stdio / SSE / streamable-http, authentification jusqu’à OAuth2) et peut appeler les outils d’un serveur MCP comme backend d’action.
- Workflow n8n : un label de webhook first-class pour brancher une automatisation n8n.
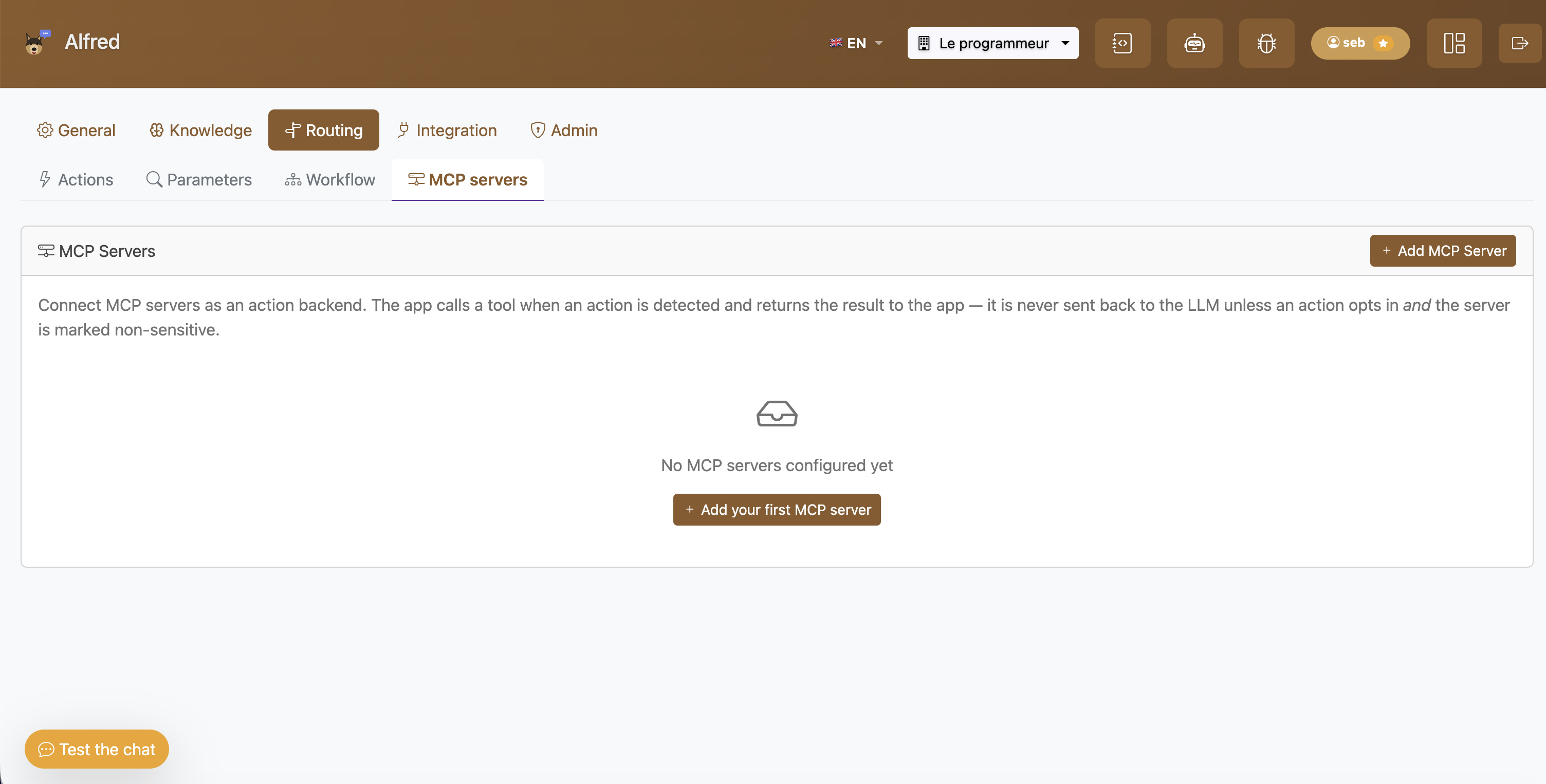 Les serveurs MCP se branchent comme backend d’action : l’outil est appelé, son résultat revient à l’app, jamais réinjecté dans le LLM (sauf opt-in explicite sur une source non sensible).
Les serveurs MCP se branchent comme backend d’action : l’outil est appelé, son résultat revient à l’app, jamais réinjecté dans le LLM (sauf opt-in explicite sur une source non sensible).
Chaque action peut demander une confirmation avant exécution, et enrichir la session de nouveaux paramètres.
Workflows guidés
Pour les parcours en plusieurs étapes (qualifier un prospect, ouvrir un ticket, collecter un besoin), Alfred embarque un moteur de workflows visuel. On enchaîne des nœuds (question, condition, fin) et le bot collecte les paramètres pas à pas. Des modèles prêts à l’emploi (par exemple “demande de devis en 4 étapes”) accélèrent la mise en place.
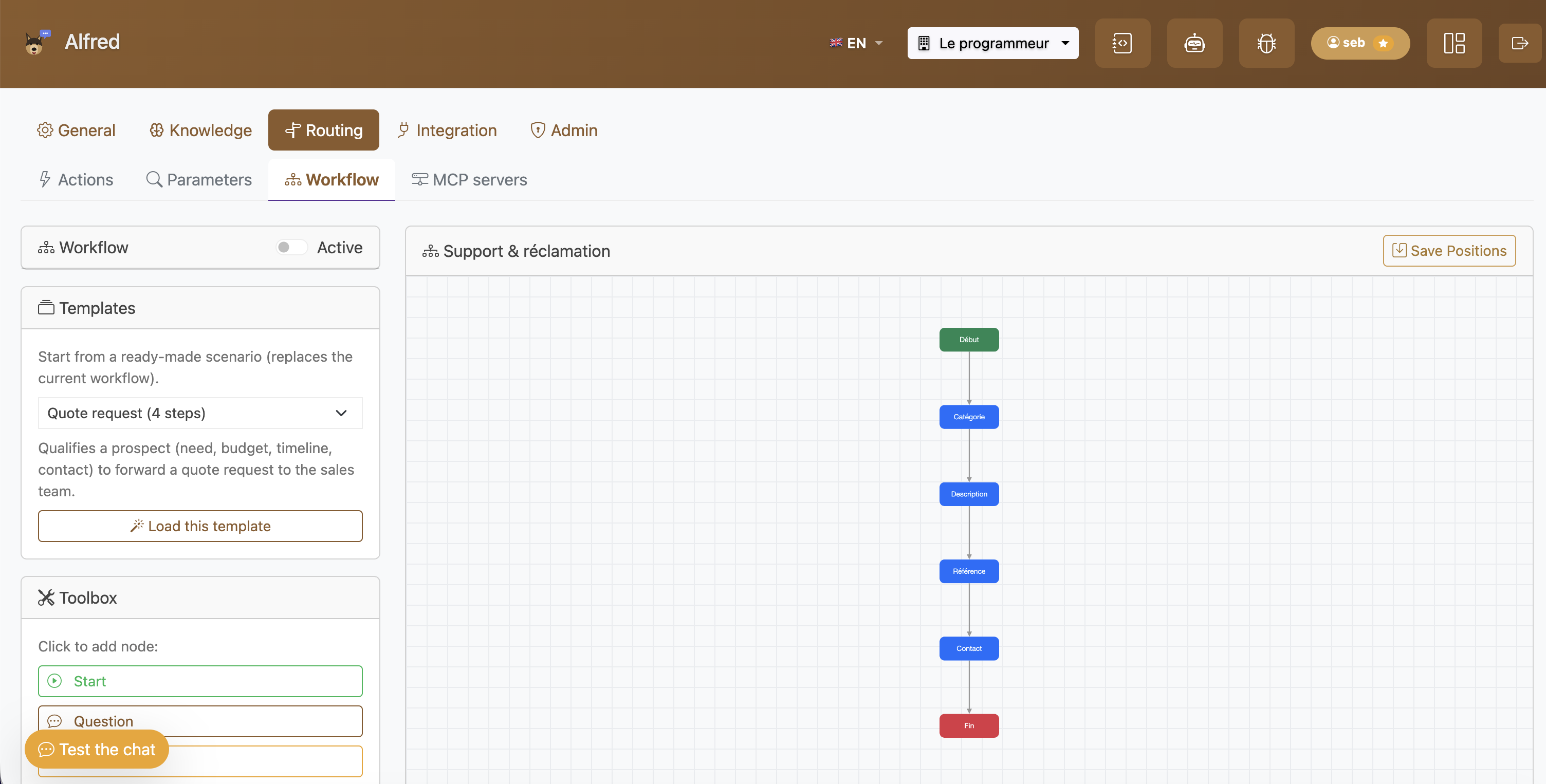 L’éditeur de workflow : un scénario “Support & réclamation” construit par nœuds, avec une bibliothèque de modèles.
L’éditeur de workflow : un scénario “Support & réclamation” construit par nœuds, avec une bibliothèque de modèles.
Base de connaissances : un RAG 100 % local
Pour répondre sur vos contenus, Alfred intègre un RAG (Retrieval-Augmented Generation) : FAQ, documents (PDF, Word, PowerPoint, Excel, Markdown) et pages web indexées via un crawler planifiable. Point important : les embeddings sont calculés localement (sentence-transformers) et stockés dans ChromaDB, isolés par client. Rien n’est envoyé à un service d’IA externe pour l’indexation.
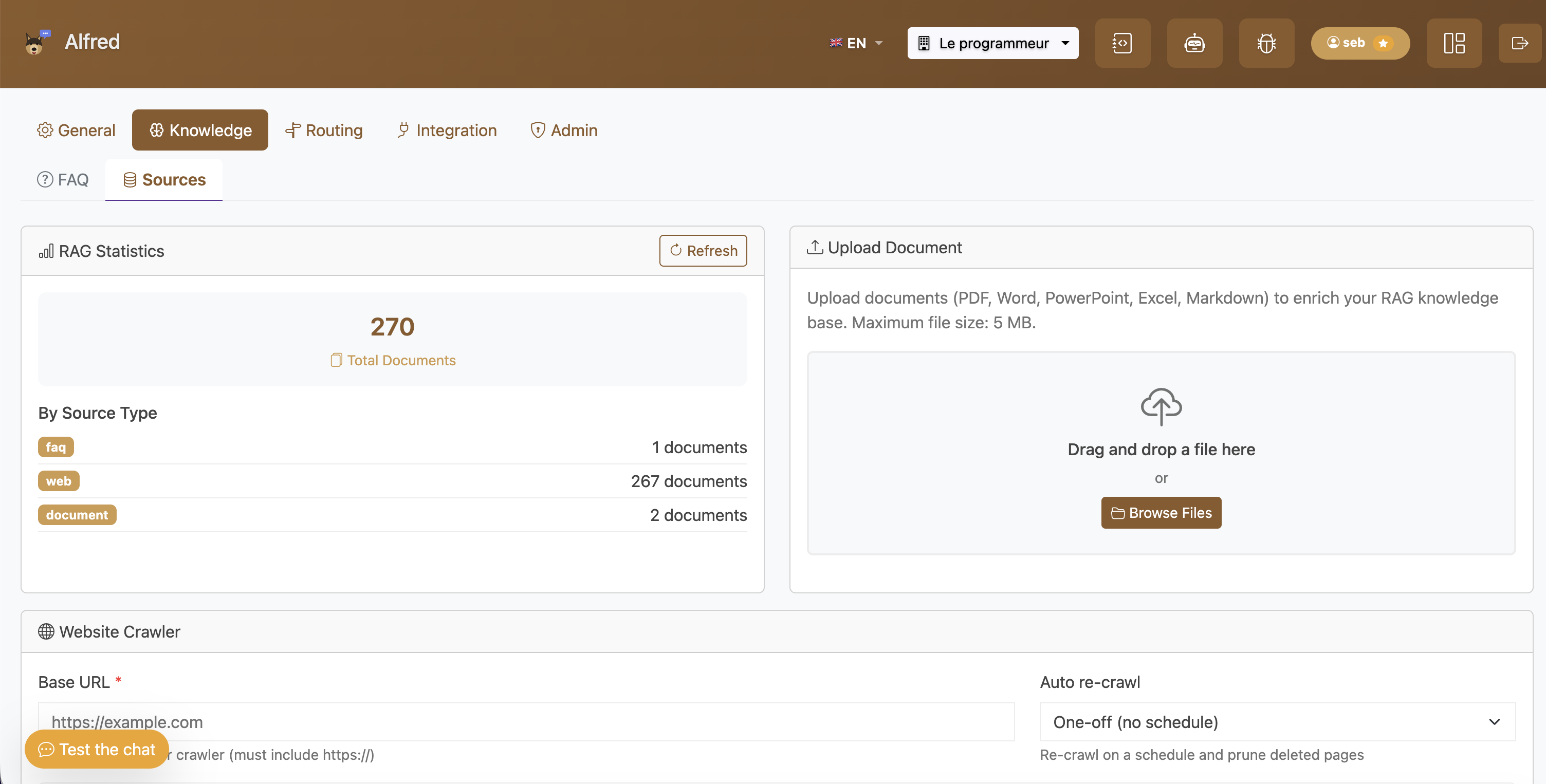 Sources de connaissance : documents importés, pages crawlées, et statistiques du RAG par type de source.
Sources de connaissance : documents importés, pages crawlées, et statistiques du RAG par type de source.
Multi-canal : web, Telegram, WhatsApp
Le même moteur alimente plusieurs canaux. On intègre le widget web en deux lignes de code, et on connecte Telegram ou WhatsApp (via Twilio) : les messages entrants passent par le même pipeline, la réponse repart dans l’application de messagerie.
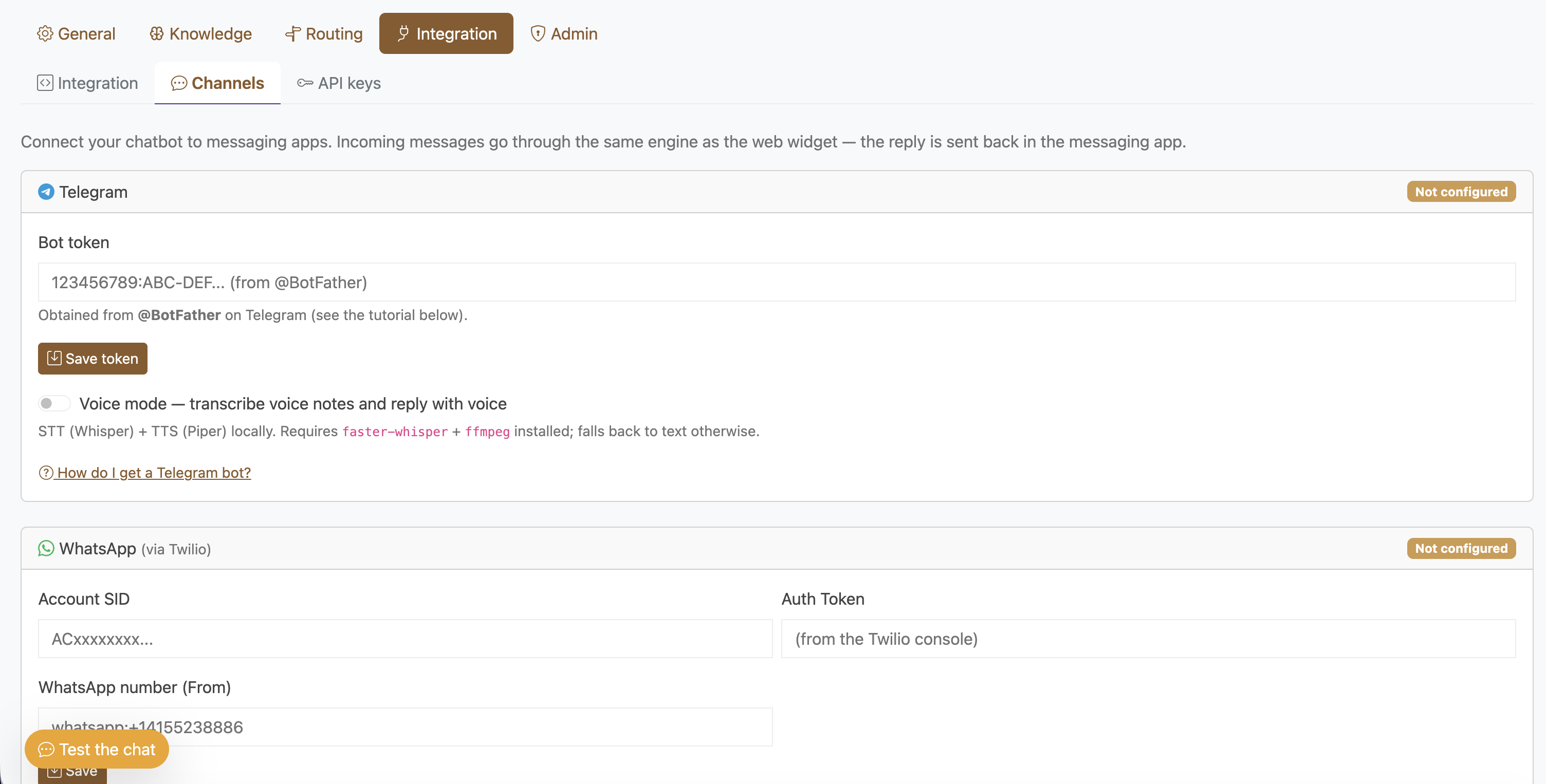 Connexion aux messageries : un bot Telegram et un numéro WhatsApp partagent le moteur du widget web.
Connexion aux messageries : un bot Telegram et un numéro WhatsApp partagent le moteur du widget web.
La voix, en local elle aussi
Alfred gère la voix de bout en bout, sans cloud : un appel vocal temps réel (bouton micro) transcrit la parole avec Whisper et répond en synthèse vocale Piper, le tout via WebSocket. Sur les messageries, le mode vocal transcrit les notes audio et répond en voix. Cohérent avec la promesse de confidentialité : la voix ne sort pas de votre serveur.
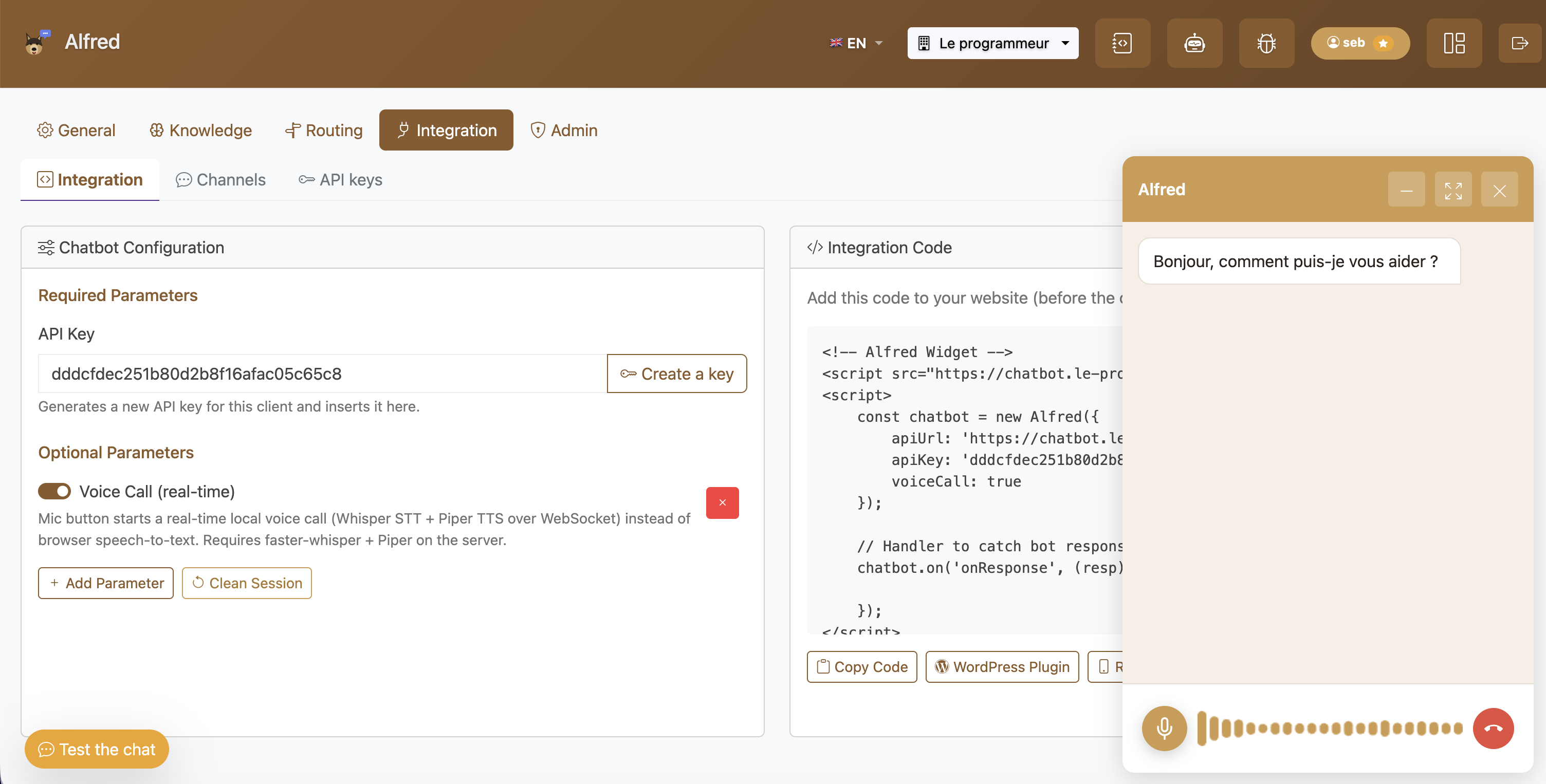 Appel vocal temps réel : STT Whisper + TTS Piper en local, activable par une simple option
Appel vocal temps réel : STT Whisper + TTS Piper en local, activable par une simple option voiceCall: true.
Paramètres, statistiques et multi-tenant
Deux briques complètent l’ensemble. Les paramètres de session portent le contexte de la conversation (identité, panier, véhicule, etc.) : ils sont injectés dès le prompt et enrichis au fil des échanges. Côté pilotage, Alfred suit la consommation de tokens et les statistiques d’intentions, pour comprendre ce que les utilisateurs demandent vraiment et maîtriser les coûts.
Le tout est multi-tenant : chaque client dispose de sa configuration, sa base de connaissances, ses actions et ses statistiques, strictement cloisonnées. Un assistant de configuration permet même de créer FAQ, actions, paramètres ou workflows en langage naturel, avec application après confirmation.
Ce que ce projet illustre
Alfred représente bien le genre de projet sur lequel j’interviens : mêler un LLM à une architecture Python rigoureuse (FastAPI, SQLAlchemy, MCP, RAG), en gardant le contrôle sur la donnée, les coûts et la fiabilité. L’IA apporte la souplesse du langage ; l’ingénierie autour garantit que le résultat est un produit, pas une démo.
Un projet de chatbot, d’assistant IA ou d’intégration LLM ? Parlons-en, et voir aussi mes expertises IA & LLM.